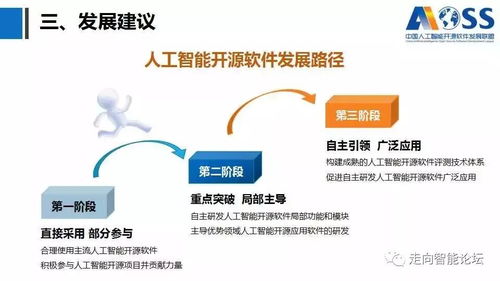
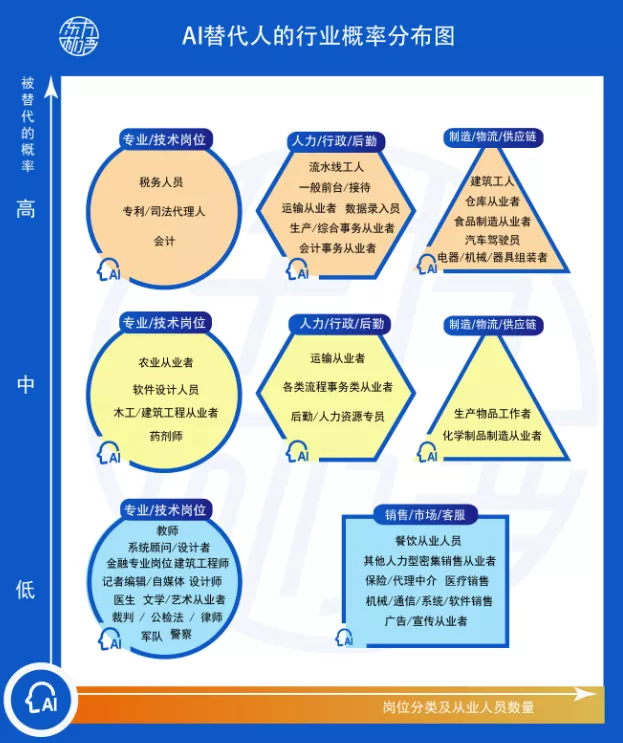
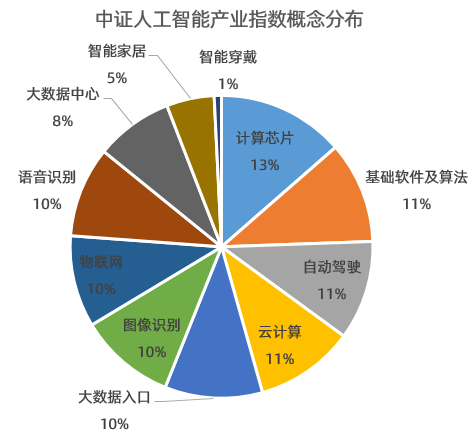
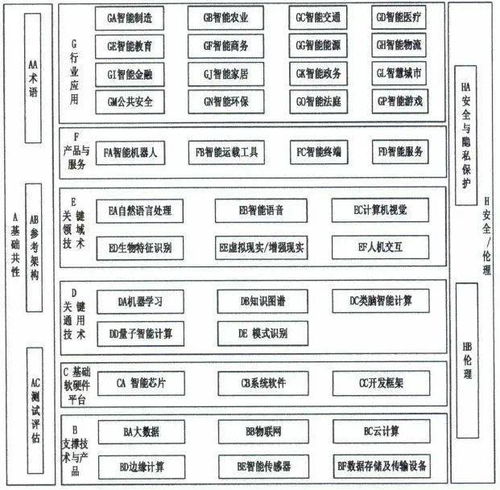
在人工智能的璀璨星河中,大模型、深度學(xué)習(xí)、生成式AI等技術(shù)術(shù)語占據(jù)了舞臺(tái)的中心。在這光鮮的技術(shù)表象之下,有一條看不見卻至關(guān)重要的基石在默默支撐著一切:數(shù)據(jù)。事實(shí)上,人工智能實(shí)踐的每一步都在強(qiáng)調(diào)一個(gè)不爭(zhēng)的真諦:即使是最頂尖的算法,其所有“智能”的來源也離不開數(shù)據(jù)的清洗、治理和建模。從人工智能基礎(chǔ)軟件的開發(fā)底層邏輯看,這不僅是一個(gè)工具棧的問題,更是一場(chǎng)對(duì)數(shù)據(jù)價(jià)值的系統(tǒng)性重塑。\n\n### 一、數(shù)據(jù)基礎(chǔ)設(shè)施是第一生產(chǎn)力的實(shí)現(xiàn)路徑\n\n很多人曾困在誤區(qū)中:是否只要引入了AI模型,企業(yè)業(yè)務(wù)就會(huì)立刻智能?答案是否定的。人工智能的所謂“高科技感”從來不是魔幻變形,而是建立在高德的數(shù)據(jù)成熟度(Data Maturity)之上。如果原始工序還未實(shí)現(xiàn)數(shù)據(jù)治理、語料采集的過程不具多樣性,或者人工標(biāo)注(ground truth)噪音過大,那么多GPU堆模型的邏輯就會(huì)阻塞在初始階段。缺乏高質(zhì)量的行業(yè)視角數(shù)據(jù)庫,公司就像要在農(nóng)田之上放高樓,無疑適得其反。從這點(diǎn)看,基礎(chǔ)軟件投入成本的最大邊際匯聚便回到了對(duì)如何搭建容納清洗規(guī)則下的適配材料結(jié)構(gòu)的問題。這種觀點(diǎn)解釋第一性原理:data決定了智能的上邊界限度,模型運(yùn)作的唯一任務(wù)只是使現(xiàn)實(shí)的分布趨于特征,這也成為解決方案團(tuán)隊(duì)開發(fā)工業(yè)情境時(shí)判斷的關(guān)鍵實(shí)踐準(zhǔn)備。“臟數(shù)據(jù)從來無法構(gòu)建穩(wěn)健連接鏈路\
數(shù)據(jù)為基 人工智能基礎(chǔ)軟件開發(fā)的根脈與藍(lán)圖
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.shexinjixie.cn/product/28.html
更新時(shí)間:2026-06-14 05:27:15